
NVIDIAеңЁGTC 24жҳҘеӯЈе ҙзҷјиЎЁдәҶе…·жңү6еӨ§еүөж–°зҡ„Blackwellжһ¶ж§ӢGPUпјҢдёҚдҪҶжҸҗдҫӣжӣҙеј·жӮҚзҡ„ж•ҲиғҪпјҢжӣҙйҷҚдҪҺ25еҖҚзёҪй«”ж“ҒжңүжҲҗжң¬пјҢйӮ„иғҪйҖҸйҒҺе…ҲйҖІз®ЎзҗҶеҠҹиғҪзё®зҹӯдјәжңҚеҷЁеҒңж©ҹжҷӮй–“гҖӮ
иЈёжҷ¶е°әеҜёйҒ”еҲ°зҸҫд»Ҡе…үзҪ©жҘөйҷҗBlackwellжҳҜе°ҲзӮәиіҮж–ҷдёӯеҝғиҷ•зҗҶз”ҹжҲҗејҸAIиҖҢиЁӯиЁҲGPUпјҢе®ғжҺЎз”ЁTSMCпјҲеҸ°з©Қйӣ»пјү4NPиЈҪзЁӢзҜҖй»һпјҢз”ұ2.08е…ҶеҖӢйӣ»жҷ¶й«”ж§ӢжҲҗпјҢжҳҜзӣ®еүҚдё–з•ҢдёҠжңҖеӨ§еһӢзҡ„GPUгҖӮе…¶жҷ¶зүҮз”ұ2зө„иЈёжҷ¶пјҲDieпјүжүҖж§ӢжҲҗпјҢжҜҸзө„иЈёжҷ¶зҡ„е°әеҜёйҒ”еҲ°зҸҫд»ҠеҚҠе°Һй«”иЈҪзЁӢдёӯе…үзҪ©зҡ„жҘөйҷҗпјҢдёҰйҖҸйҒҺй »еҜ¬й«ҳйҒ”10 TB/sзҡ„NV-HBIпјҲNVIDIA High-Bandwidth Interfaceпјүжҷ¶зүҮе°Қжҷ¶зүҮдә’йҖЈпјҲChip-to-Chip InterconnectionпјүзӣёйҖЈпјҢи®“2зө„иЈёжҷ¶жҲҗзӮәе–®дёҖжҷ¶зүҮдёҰзўәдҝқиЁҳжҶ¶й«”дёҖиҮҙжҖ§пјҲCoherentпјүпјҢиғҪеӨ е…ұдә«е®№йҮҸй«ҳйҒ”192 GBзҡ„HBM3eй«ҳй »еҜ¬иЁҳжҶ¶й«”гҖӮ
- 延伸й–ұи®Җпјҡ
- GTC 24пјҡBlackwellе…Ёж–°жһ¶ж§Ӣеё¶дҫҶ5еҖҚж•ҲиғҪиЎЁзҸҫпјҲжң¬ж–Үпјү
- GTC 24пјҡBlackwellжһ¶ж§Ӣи©іи§ЈпјҲдёӢпјүпјҢзңӢжҮӮB100гҖҒB200гҖҒGB200гҖҒGB200 NVL72жҲҗе“Ўзҡ„зіҫзөҗз“ңи‘ӣпјҲе·ҘдҪңдёӯпјү
- GTC 2024жҳҘеӯЈе ҙзі»еҲ—е ұе°Һзӣ®йҢ„
BlackwellеңЁTensorж ёеҝғпјҲзЎ¬й«”еұӨйқўпјүиҲҮTensorRT-LLMгҖҒNemoйҒӢз®—жЎҶжһ¶пјҲи»ҹй«”еұӨйқўпјүеҚ”еҗҢйҒӢдҪңд№ӢдёӢж”ҜжҸҙ第2д»ЈTransformerеј•ж“ҺпјҢиғҪеӨ еҠ йҖҹеӨ§еһӢиӘһиЁҖжЁЎеһӢиҲҮж··еҗҲе°Ҳ家пјҲMixture-of-ExpertsпјүAIжЁЎеһӢеңЁиЁ“з·ҙиҲҮжҺЁи«–жҷӮзҡ„йҒӢз®—ж•ҲиғҪпјҢдёҰдё”иғҪеӨ ж”ҜжҸҙеҢ…еҗ«з”ұзӨҫзҫӨе®ҡзҫ©зҡ„FP4иҲҮFP6иіҮж–ҷйЎһеһӢзҡ„жө®й»һйҒӢз®—пјҢд»ҘеҸҠз”ұзӨҫзҫӨе®ҡзҫ©зҡ„еҫ®ж“ҙе……ж јејҸпјҲMicroscaling FormatsпјүпјҢиғҪеӨ жҸҗдҫӣй«ҳжә–зўәеәҰиҲҮй«ҳеҗһеҗҗйҮҸзҡ„йҒӢз®—жҲҗж•ҲгҖӮ
е…Ёж–°зҡ„Micro-Tensor ScalingжҠҖиЎ“иғҪеӨ ж”ҜжҸҙеӢ•ж…ӢзҜ„еңҚз®ЎзҗҶжј”з®—жі•пјҲDynamic Range Management AlgorithmпјүгҖҒзІҫзҙ°зІ’еәҰж“ҙе……пјҲFine-Grain ScalingпјүпјҢдёҰж”ҜжҸҙFP4иіҮж–ҷйЎһеһӢйҒӢз®—пјҢдё”жңҖдҪіеҢ–йҒӢз®—ж•ҲиғҪиҲҮзІҫжә–еәҰпјҢи®“Blackwellзҡ„FP4 Tensorж ёеҝғCoreиғҪеӨ йҒ”еҲ°йӣҷеҖҚиЁҳжҶ¶й«”еҸғж•ёй »еҜ¬пјҢдёҰи®“GPUиғҪеӨ е®№зҙҚйӣҷеҖҚе°әеәҰзҡ„AIжЁЎеһӢгҖӮ
В
 в–І NVIDIAеүөиҫҰдәәжҡЁеҹ·иЎҢй•·й»ғд»ҒеӢіеңЁGTC 2024жҳҘеӯЈе ҙй–Ӣ幕演иӘӘдёӯеұ•зӨәBlackwell GPUпјҲе·Ұпјүд»ҘеҸҠеүҚд»ЈHopperжһ¶ж§Ӣзҡ„H100пјҢеҸҜд»ҘжҳҺйЎҜзңӢеҮә2иҖ…зҡ„е°әеҜёе·®з•°гҖӮ
в–І NVIDIAеүөиҫҰдәәжҡЁеҹ·иЎҢй•·й»ғд»ҒеӢіеңЁGTC 2024жҳҘеӯЈе ҙй–Ӣ幕演иӘӘдёӯеұ•зӨәBlackwell GPUпјҲе·Ұпјүд»ҘеҸҠеүҚд»ЈHopperжһ¶ж§Ӣзҡ„H100пјҢеҸҜд»ҘжҳҺйЎҜзңӢеҮә2иҖ…зҡ„е°әеҜёе·®з•°гҖӮ
 в–І Blackwell GPUжң¬й«”з”ұжҸҗдҫӣеӨҡзЁ®2.08е…ҶеҖӢйӣ»жҷ¶й«”ж§ӢжҲҗпјҢжҳҜзӣ®еүҚдё–з•ҢдёҠжңҖеӨ§еһӢзҡ„GPUдёҰжҸҗдҫӣеӨҡзЁ®е…ҲйҖІе№іеҸ°еҠҹиғҪгҖӮ
в–І Blackwell GPUжң¬й«”з”ұжҸҗдҫӣеӨҡзЁ®2.08е…ҶеҖӢйӣ»жҷ¶й«”ж§ӢжҲҗпјҢжҳҜзӣ®еүҚдё–з•ҢдёҠжңҖеӨ§еһӢзҡ„GPUдёҰжҸҗдҫӣеӨҡзЁ®е…ҲйҖІе№іеҸ°еҠҹиғҪгҖӮ
 в–І GB200 SuperchipдёҠе…·жңү2зө„Blackwell GPUпјҢеҸҜд»ҘзңӢеҲ°Blackwell GPUжҷ¶зүҮжҳҜз”ұ2зө„иЈёжҷ¶ж§ӢжҲҗгҖӮ
в–І GB200 SuperchipдёҠе…·жңү2зө„Blackwell GPUпјҢеҸҜд»ҘзңӢеҲ°Blackwell GPUжҷ¶зүҮжҳҜз”ұ2зө„иЈёжҷ¶ж§ӢжҲҗгҖӮ
 в–І Blackwell GPUеңЁFP8иіҮж–ҷйЎһеһӢзҡ„йҒӢз®—ж•ҲиғҪзӮәHopperзҡ„2.5еҖҚпјҢиӢҘж”№з”Ёж–°зҡ„FP4иіҮж–ҷйЎһеһӢеүҮеҸҜйҒ”еҲ°5еҖҚйҒӢз®—ж•ҲиғҪгҖӮ
в–І Blackwell GPUеңЁFP8иіҮж–ҷйЎһеһӢзҡ„йҒӢз®—ж•ҲиғҪзӮәHopperзҡ„2.5еҖҚпјҢиӢҘж”№з”Ёж–°зҡ„FP4иіҮж–ҷйЎһеһӢеүҮеҸҜйҒ”еҲ°5еҖҚйҒӢз®—ж•ҲиғҪгҖӮ
 в–І иҲҮе…ҲеүҚPascalжһ¶ж§ӢзӣёжҜ”пјҢBlackwellеңЁ8е№ҙе…§йҒ”еҲ°и¶…1,000еҖҚзҡ„ж•ҲиғҪжҸҗеҚҮгҖӮ
в–І иҲҮе…ҲеүҚPascalжһ¶ж§ӢзӣёжҜ”пјҢBlackwellеңЁ8е№ҙе…§йҒ”еҲ°и¶…1,000еҖҚзҡ„ж•ҲиғҪжҸҗеҚҮгҖӮ
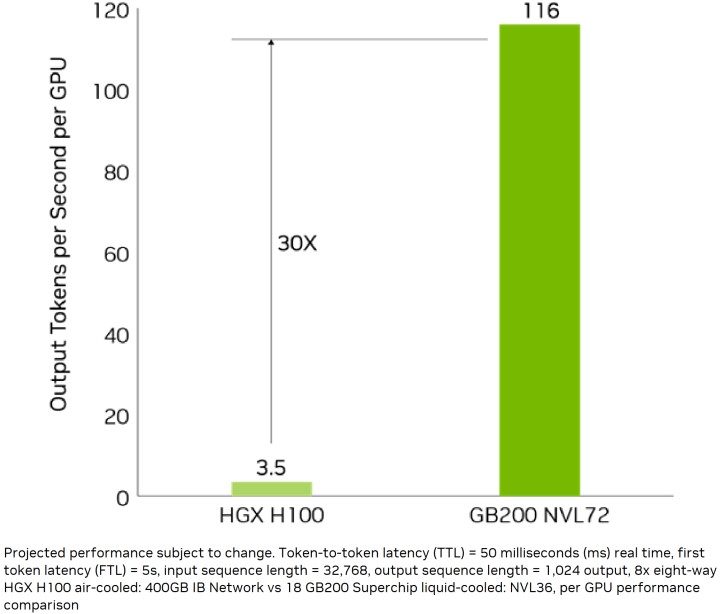 в–І ж №ж“ҡNVIDIAжҸҗдҫӣзҡ„ж•ёж“ҡпјҢBlackwellжһ¶ж§Ӣзҡ„GB200 NVL72иғҪеё¶дҫҶ30еҖҚж–јеүҚд»ЈHGX H100зҡ„еӨ§еһӢиӘһиЁҖTokenијёеҮәж•ҲиғҪгҖӮ
в–І ж №ж“ҡNVIDIAжҸҗдҫӣзҡ„ж•ёж“ҡпјҢBlackwellжһ¶ж§Ӣзҡ„GB200 NVL72иғҪеё¶дҫҶ30еҖҚж–јеүҚд»ЈHGX H100зҡ„еӨ§еһӢиӘһиЁҖTokenијёеҮәж•ҲиғҪгҖӮ
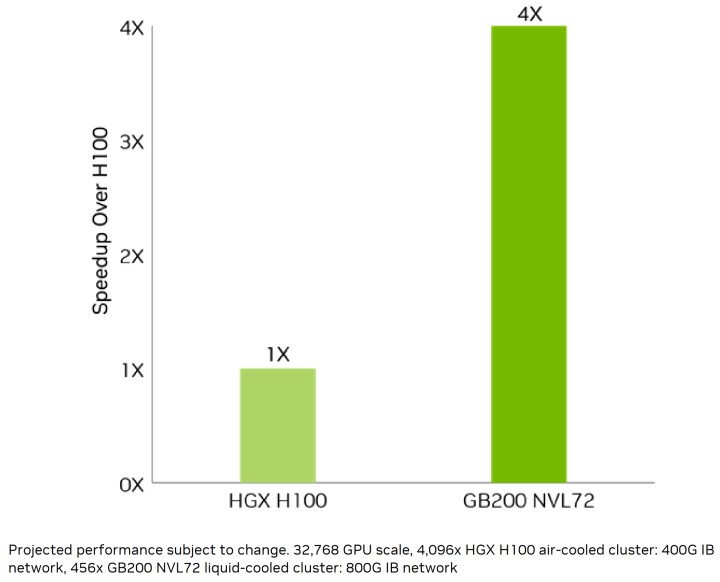 в–І еңЁ1.8T GPT MoEжЁЎеһӢзҡ„иЁ“з·ҙйғЁеҲҶпјҢGB200 NVL72е…·жңү4еҖҚж–јHGX H100зҡ„иЎЁзҸҫгҖӮ
в–І еңЁ1.8T GPT MoEжЁЎеһӢзҡ„иЁ“з·ҙйғЁеҲҶпјҢGB200 NVL72е…·жңү4еҖҚж–јHGX H100зҡ„иЎЁзҸҫгҖӮ
Blackwell GPUд№ҹеҠ е…ҘдәҶиЁұеӨҡе°ҲзӮәдјҒжҘӯиҲҮиіҮж–ҷдёӯеҝғжҮүз”ЁиЁӯиЁҲзҡ„еҠҹиғҪпјҢдҫӢеҰӮRASеј•ж“ҺпјҲReliability, Availability,and Serviceability EngineпјҢеҸҜйқ жҖ§гҖҒеҸҜз”ЁжҖ§е’ҢеҸҜз¶ӯиӯ·жҖ§еј•ж“ҺпјүжңғйҖҸйҒҺе®Ңж•ҙзҡ„иҮӘжҲ‘жӘўжҹҘж©ҹеҲ¶жҗӯй…Қз”ұAIй©…еӢ•зҡ„еӨ§ж•ёж“ҡеҲҶжһҗпјҢй җжё¬зі»зөұдёӯеҸҜиғҪжңғеҮәзӢҖжіҒзҡ„жӘўжҹҘй»һпјҲChickpointпјүпјҢи®“з¶ӯиӯ·еңҳйҡҠеҸҜд»ҘеҚіж—©иҷ•зҗҶпјҢжҲ–жҳҜеңЁйқһдёҚеҫ—д»ҘйңҖиҰҒй—ңж©ҹжҷӮпјҢд№ҹеҸҜд»Ҙе®үжҺ’еңЁиЎқж“ҠжңҖе°Ҹзҡ„жҷӮй–“з°ЎйҖІиЎҢз¶ӯиӯ·пјҢеӨ§е№…зё®зҹӯдјәжңҚеҷЁзҡ„еҒңж©ҹжҷӮй–“пјҲDowntimeпјүгҖӮ
NVIDIAд№ҹе°Үж©ҹеҜҶйҒӢз®—пјҲConfidential ComputingпјүеҠҹиғҪз”ұCPUжҺЁе»ЈиҮіGPUпјҢж“ҙеӨ§еҸҜдҝЎд»»еҹ·иЎҢз’°еўғпјҲTrusted Execution EnvironmentпјҢTEEпјүзҡ„зҜ„еңҚпјҢи®“Blackwell жҲҗзӮәйҰ–ж¬ҫж”ҜжҸҙTEE-I/Oзҡ„GPUпјҢиғҪеӨ жҸҗдҫӣжӣҙеҝ«гҖҒжӣҙе®үе…ЁгҖҒеҸҜиӯүжҳҺпјҲEvidence-Based Attestableпјүзҡ„иіҮе®үдҝқиӯ·пјҢдёҰдё”жҸҗдҫӣе№ҫд№ҺзӯүеҗҢж–јжңӘеҠ еҜҶжЁЎејҸзҡ„иіҮж–ҷеҗһеҗҗж•ҲиғҪпјҢи®“е®ўжҲ¶иғҪеӨ зўәдҝқAIжҷәж…§иІЎз”ўж¬ҠпјҢдёҰзўәдҝқж©ҹеҜҶAIиЁ“з·ҙгҖҒжҺЁи«–зҗҶиҲҮиҒҜйӮҰеӯёзҝ’пјҲFederated Learningпјүзҡ„е®үе…ЁжҖ§гҖӮ
зӮәдәҶжҸҗй«ҳиіҮж–ҷеӮіијёзҡ„ж•ҲзҺҮпјҢNVIDIAд№ҹдёҖж”№еӮізөұиіҮж–ҷеҲҶжһҗе’ҢиіҮж–ҷеә«йҒӢз®—иІ ијүйҖҸйҒҺCPUиҷ•зҗҶиіҮж–ҷз·©ж…ўеҸҲз№Ғз‘Јзҡ„жөҒзЁӢпјҢи®“Blackwell GPUеҠ йҖҹж”ҜжҸҙеҢ…жӢ¬Apache SparkеңЁе…§зҡ„иіҮж–ҷеә«жЎҶжһ¶пјҢдёҰе…§е»әи§ЈеЈ“зё®ж•ҲиғҪй«ҳйҒ”800 GB/sзҡ„и§ЈеЈ“зё®еј•ж“ҺпјҢдёҰж”ҜжҸҙLZ4гҖҒSnappyгҖҒDeflateзӯүжңҖж–°еЈ“зё®ж јејҸпјҢе…ЁйқўеҠ йҖҹиіҮж–ҷеә«жҹҘи©ўпјҲDatabase Queryпјүз®Ўз·ҡж•ҲиғҪгҖӮ
Blackwell GPUжҗӯй…Қй »еҜ¬й«ҳйҒ”8 TB/sзҡ„HBM3eй«ҳй »еҜ¬иЁҳжҶ¶й«”д»ҘеҸҠйҖҸйҒҺNVLink-C2Cдә’йҖЈжҠҖиЎ“йҖЈжҺҘиҮіGrace CPUпјҢеҸҜд»ҘжҸҗдҫӣ18еҖҚж–јеӮізөұCPUжҲ–6еҖҚж–јеүҚд»ЈH100 GPUзҡ„жҹҘи©ўж•ҲиғҪжё¬и©ҰпјҲQuery BenchmarkпјүпјҢйҒ”жҲҗиіҮж–ҷеҲҶжһҗе’ҢиіҮж–ҷ科еӯёпјҲData Scienceпјүзҡ„жңҖй«ҳйҒӢз®—ж•ҲиғҪгҖӮ
дёҠиҝ°зҡ„ж•ҲиғҪгҖҒйҒӢз®—еҜҶеәҰгҖҒйӣ»еҠӣж•ҲзҺҮгҖҒRASж”№е–„пјҢе°ҚдјәжңҚеҷЁзҡ„жҲҗжң¬йғҪжңүжӯЈйқўе№«еҠ©пјҢеҸҰдёҖж–№йқўNVIDIAд№ҹеңЁBlackwellдё–д»Јз©ҚжҘөжҺЁеӢ•еҫһз©әеҶ·иҪүжҸӣеҲ°ж°ҙеҶ·зҡ„ж•ЈзҶұж–№жЎҲпјҢйҖҸйҒҺж•ЈзҶұе·ҘдҪңж¶Ій«”еҫӘз’°ж–јж©ҹжһ¶е…§зҡ„CPUгҖҒGPUзӯүй«ҳжә«е…ғ件д»ҘеҸҠеӨ–йғЁж•ЈзҶұеҷЁпјҲRadiatorпјҢеҠҹиғҪзӯүеҗҢж–јеҖӢдәәйӣ»и…Ұж°ҙеҶ·зі»зөұзҡ„ж•ЈзҶұжҺ’пјүпјҢйҖІдёҖжӯҘйҷҚдҪҺж©ҹжҲҝз©әиӘҝзҡ„иғҪжәҗж¶ҲиҖ—гҖӮ
ж•ҙй«”иҖҢиЁҖпјҢеңЁеҹ·иЎҢиҗ¬е„„зө„еҸғж•ёзҡ„AIжЁЎеһӢжўқ件дёӢпјҢжҺЎз”Ёж°ҙеҶ·ж–№жЎҲзҡ„GB200иғҪијғжҺЎз”Ёз©әеҶ·зҡ„H100йҷҚдҪҺ25еҖҚзёҪй«”ж“ҒжңүжҲҗжң¬пјҲTotal Cost of OwnershipпјҢTCOпјүпјҢе°Қж–јиіҮж–ҷдёӯеҝғдҫҶиӘӘзӣёз•¶жңүеҗёеј•еҠӣгҖӮ
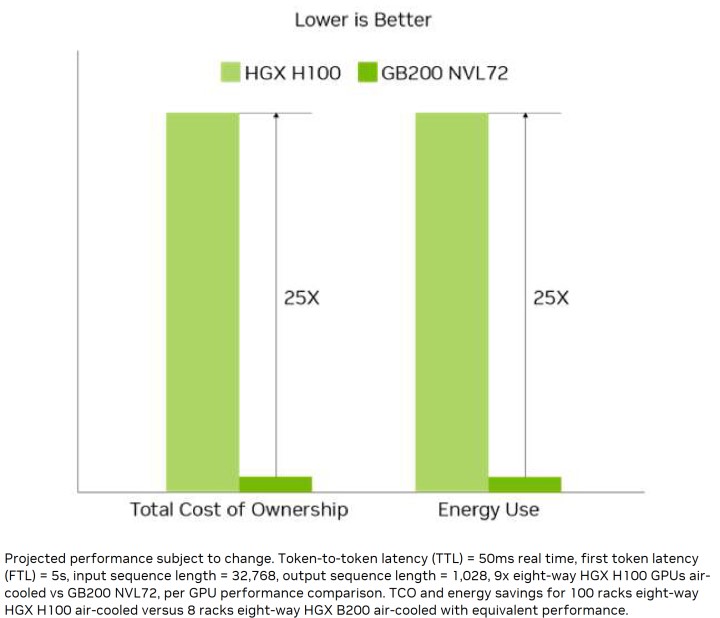 в–І GB200 NVL72еңЁTCOиҲҮйӣ»еҠӣж¶ҲиҖ—йғЁеҲҶзҡ„иЎЁзҸҫе„Әж–јHGX H100зҙ„25еҖҚгҖӮ
в–І GB200 NVL72еңЁTCOиҲҮйӣ»еҠӣж¶ҲиҖ—йғЁеҲҶзҡ„иЎЁзҸҫе„Әж–јHGX H100зҙ„25еҖҚгҖӮ
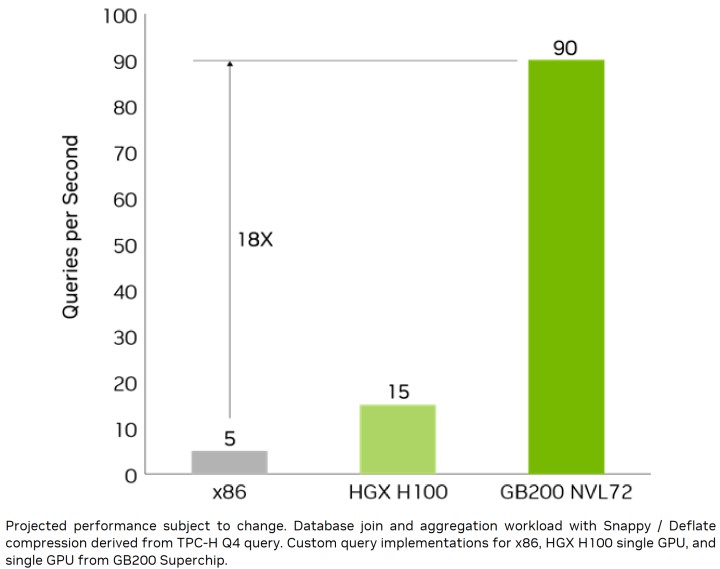 в–І еҸ—зӣҠж–јзү№еҢ–жһ¶ж§ӢиҲҮи§ЈеЈ“зё®еј•ж“Һзҡ„е„ӘеӢўпјҢGB200 NVL72еңЁиіҮж–ҷеә«жҹҘи©ўзҡ„ж•ҲзҺҮж ЎеӮізөұx86жһ¶ж§Ӣзі»зөұй«ҳеҮә18еҖҚгҖӮ
в–І еҸ—зӣҠж–јзү№еҢ–жһ¶ж§ӢиҲҮи§ЈеЈ“зё®еј•ж“Һзҡ„е„ӘеӢўпјҢGB200 NVL72еңЁиіҮж–ҷеә«жҹҘи©ўзҡ„ж•ҲзҺҮж ЎеӮізөұx86жһ¶ж§Ӣзі»зөұй«ҳеҮә18еҖҚгҖӮ
Blackwell GPUдёҚдҪҶжҳҜзӣ®еүҚжңҖеј·зҡ„AIеҠ йҖҹйҒӢз®—е–®е…ғпјҢиҖҢдё”йӮ„еҸҜйҖҸйҒҺдёІжҺҘеӨҡзө„GPUж–№ејҸйҖІиЎҢж°ҙе№іејҸж“ҙе……пјҲScale OutпјүпјҢеӨ§е№…еј·еҢ–зёҪй«”ж•ҲиғҪиҲҮеҗһеҗҗйҮҸпјҢзӯҶиҖ…е°Үж–јдёӢзҜҮж–Үз« йҖІиЎҢи©ізҙ°иӘӘжҳҺгҖӮ
пјҲеӣһеҲ°GTC 2024жҳҘеӯЈе ҙзі»еҲ—е ұе°Һзӣ®йҢ„пјү
еҠ е…ҘTе®ўйӮҰFacebookзІүзөІеңҳ еӣәе®ҡй“ҫжҺҘ 'GTC 24пјҡBlackwellе…Ёж–°жһ¶ж§Ӣеё¶дҫҶ5еҖҚж•ҲиғҪиЎЁзҸҫ' жҸҗдәӨ: April 1, 2024, 5:00pm CST